Auto-Atención & Transformers
S2: Atención Multi-Cabeza y Codificación Posicional
2026-04-15
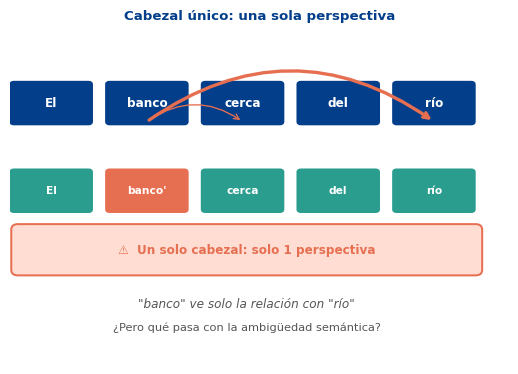
La Idea: Múltiples Perspectivas Simultáneas
En lugar de una proyección, usar \(h\) proyecciones
Cada cabezal \(i\) aprende sus propias matrices \(\mathbf{W}_Q^{(i)}, \mathbf{W}_K^{(i)}, \mathbf{W}_V^{(i)}\) y puede especializarse en un tipo diferente de relación:
\[\text{head}_i = \text{Attention}(\mathbf{Q}\mathbf{W}_Q^{(i)},\; \mathbf{K}\mathbf{W}_K^{(i)},\; \mathbf{V}\mathbf{W}_V^{(i)})\]
Sus salidas se concatenan y se proyectan:
\[\text{MultiHead}(\mathbf{Q},\mathbf{K},\mathbf{V}) = \text{Concat}(\text{head}_1, \ldots, \text{head}_h)\,\mathbf{W}^O\]
Dimensiones
- \(\mathbf{W}_Q^{(i)}, \mathbf{W}_K^{(i)} \in \mathbb{R}^{d_\text{model} \times d_k}\), con \(d_k = d_\text{model}/h\)
- La concatenación produce \(h \cdot d_k = d_\text{model}\) → proyección \(\mathbf{W}^O \in \mathbb{R}^{d_\text{model} \times d_\text{model}}\)
Tip
En Vaswani et al. (2017): \(d_\text{model}=512\), \(h=8\), \(d_k=d_v=64\).
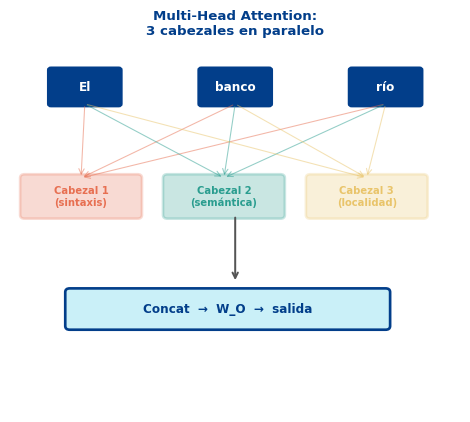
Visualización: Cada Cabezal Aprende Algo Diferente

Note
Estos patrones son ilustrativos. En modelos reales (BERT), Clark et al. (2019) identificaron cabezales especializados en: tokens directamente anteriores/siguientes, tokens relacionados sintácticamente, el token [SEP], y más.
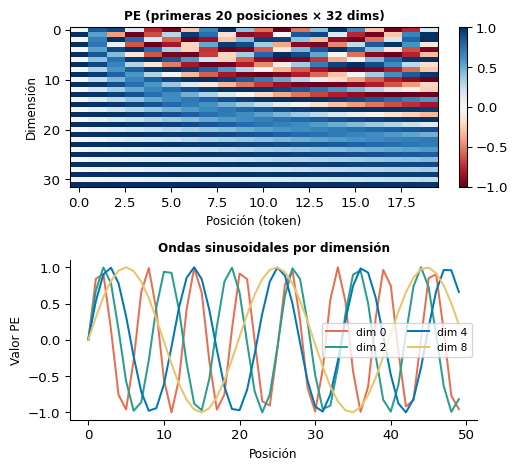
Codificación Posicional Sinusoidal
Definición (Vaswani et al., 2017)
\[\text{PE}(pos, 2i) = \sin\!\left(\frac{pos}{10000^{2i/d_\text{model}}}\right)\]
\[\text{PE}(pos, 2i+1) = \cos\!\left(\frac{pos}{10000^{2i/d_\text{model}}}\right)\]
- \(pos\): posición del token en la secuencia (\(0, 1, \ldots, T-1\))
- \(i\): índice de la dimensión del embedding (\(0, 1, \ldots, d/2-1\))
- Dimensiones pares: seno, dimensiones impares: coseno
¿Por qué funciona?
- Cada posición tiene un vector único
- El modelo puede inferir distancia relativa entre posiciones: \(\text{PE}(pos+k)\) es una transformación lineal de \(\text{PE}(pos)\)
- No requiere entrenamiento — es determinista
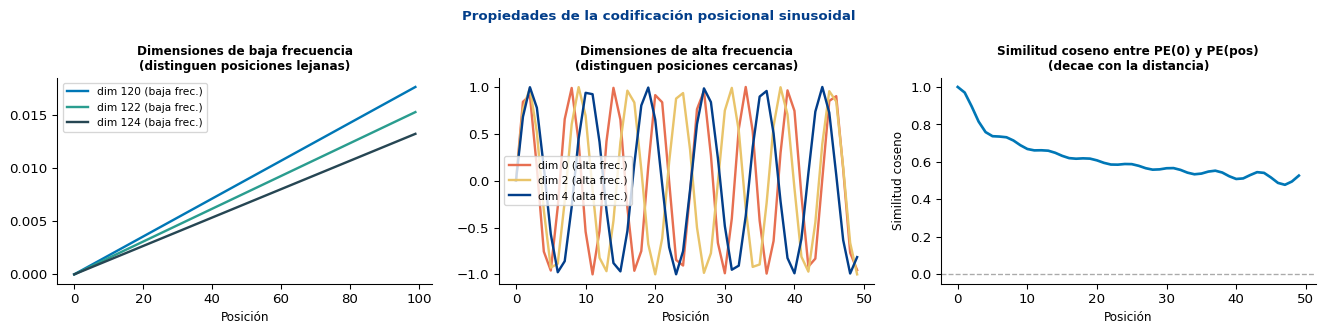
¿Por Qué Ondas de Diferentes Frecuencias?
Tip
La similitud coseno decae con la distancia → el modelo puede inferir que posiciones cercanas son más similares que posiciones lejanas, sin haberlo sido entrenado explícitamente para ello.
Visualización: PE en el Espacio de Atención
