Redes Neuronales Convolucionales para NLP
S3: Comparación RNNs vs. CNNs para Clasificación
2026-04-11
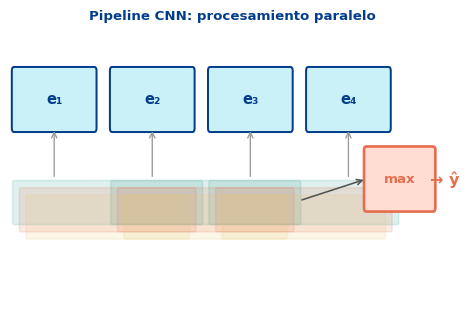
El Pipeline CNN
Texto → Embeddings → Conv1D → Pooling → ClasificadorPaso a paso: 1. Tokens → embeddings: matriz \(\mathbf{E} \in \mathbb{R}^{T \times d}\) 2. Filtros convolucionales en paralelo: \[h_i = \text{ReLU}(\mathbf{W} \cdot \mathbf{e}_{i:i+k-1} + b)\] 3. Global max pooling: \(\hat{h} = \max_i h_i\) 4. \(\hat{y} = \text{softmax}(\mathbf{W}\hat{\mathbf{h}} + \mathbf{b})\)
Note
Sin dependencia temporal: todos los \(h_i\) se calculan simultáneamente — el procesamiento es completamente paralelo.
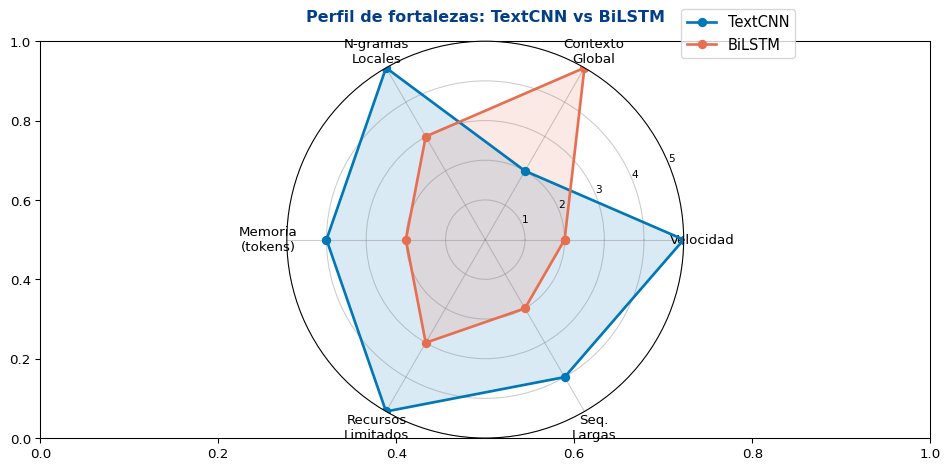
Eje 1: Paralelismo
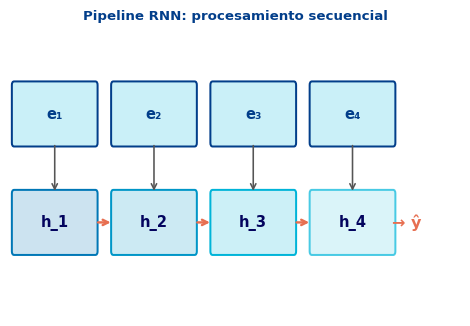
RNN — Secuencial por diseño
\[\mathbf{h}_t = f(\mathbf{h}_{t-1}, \mathbf{e}_t)\]
- Cada paso depende del anterior
- No se puede paralelizar a lo largo de \(T\)
- GPU infrautilizada para secuencias cortas
- Tiempo \(\propto T\) (longitud de la secuencia)
CNN — Paralelo por diseño
\[h_i = \text{ReLU}(\mathbf{W} \cdot \mathbf{e}_{i:i+k-1} + b)\]
- Todos los \(h_i\) son independientes entre sí
- Se calculan simultáneamente con
nn.Conv1d - GPU utilizada al máximo
- Tiempo \(\propto \log T\) en la práctica
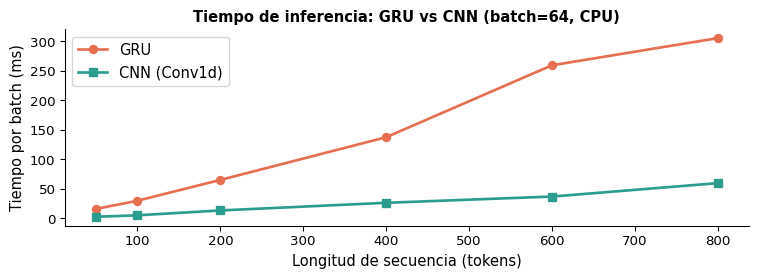
Curvas de Aprendizaje

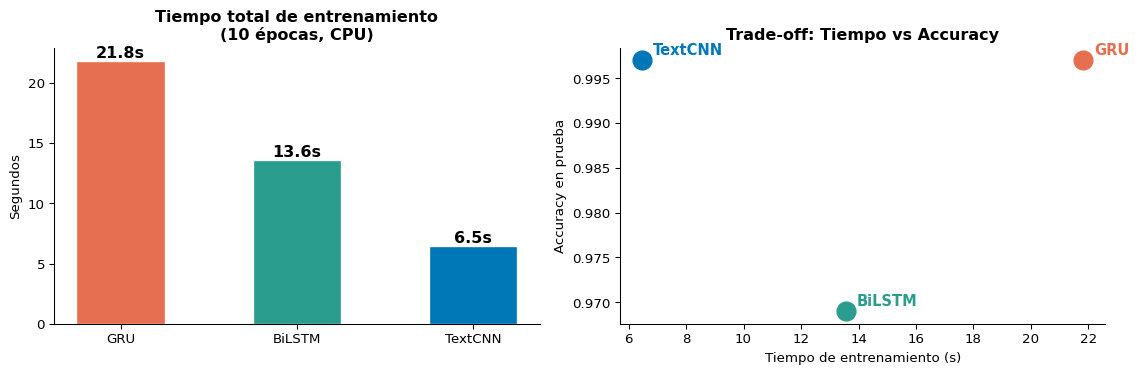
Comparación de Tiempos de Entrenamiento
Important
Observación clave: TextCNN alcanza accuracy competitivo en significativamente menos tiempo. La diferencia de velocidad se amplifica con GPUs y secuencias más largas.
Guía de Decisión Práctica

Resumen Visual
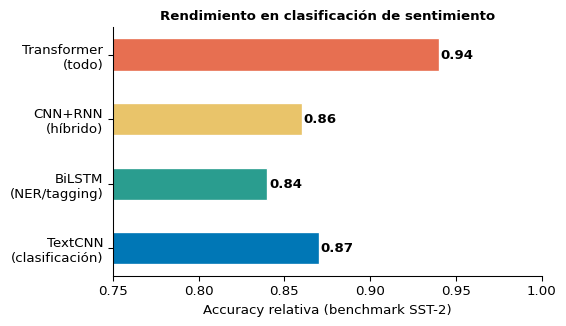
Benchmark Extendido: Incluyendo CNN+RNN
Resumen final:
Modelo Acc Test Tiempo (s)
------------------------------------
GRU 0.997 21.81
BiLSTM 0.969 13.56
TextCNN 0.997 6.47
CNN+RNN 0.986 21.90
Reflexión: ¿Cuál Es el Mejor Modelo?
No hay respuesta universal
“All models are wrong, but some are useful.”
— George Box
La elección depende de:
- Tarea: clasificación vs. generación vs. etiquetado
- Datos: longitud de secuencias, tamaño del dataset
- Recursos: GPU disponible, latencia requerida
- Baseline razonable: TextCNN es a menudo el mejor punto de partida por su velocidad
El panorama hoy (2024)
Important
Los Transformers (próxima semana) superan a CNN y RNN, pero requieren más datos y recursos.