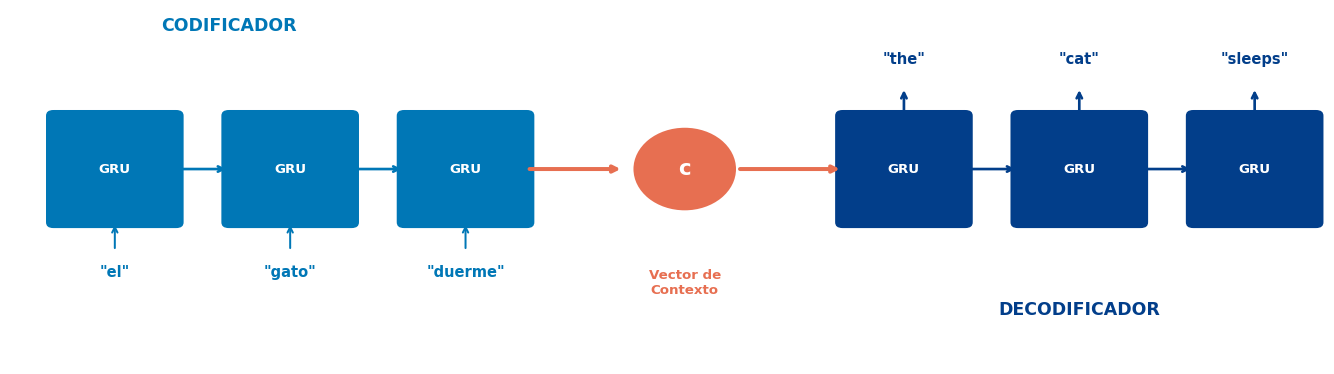
Code
import torch
import torch.nn as nn
class Encoder(nn.Module):
def __init__(self, vocab_size, embed_dim, hidden_dim, n_layers=1, dropout=0.0):
super().__init__()
self.embedding = nn.Embedding(vocab_size, embed_dim)
self.rnn = nn.GRU(embed_dim, hidden_dim,
num_layers=n_layers, batch_first=True,
dropout=dropout if n_layers > 1 else 0.0)
def forward(self, src):
"""
src: (batch, src_len) — índices de tokens
Retorna: hidden (n_layers, batch, hidden_dim) — vector de contexto
"""
embedded = self.embedding(src) # (batch, src_len, embed_dim)
outputs, hidden = self.rnn(embedded) # hidden: (n_layers, batch, hidden_dim)
return hidden # Último estado oculto = contexto
# Ejemplo
enc = Encoder(vocab_size=100, embed_dim=32, hidden_dim=64)
x = torch.randint(0, 100, (4, 8)) # batch=4, longitud=8
context = enc(x)
print(f"Entrada: {x.shape}") # (4, 8)
print(f"Contexto: {context.shape}") # (1, 4, 64)Entrada: torch.Size([4, 8])
Contexto: torch.Size([1, 4, 64])