# Contar parámetrostotal_params =sum(p.numel() for p in modelo.parameters())print(f"\nParámetros totales: {total_params}")for nombre, param in modelo.named_parameters():print(f" {nombre}: {param.shape} = {param.numel()} params")
PyTorch acumula gradientes por defecto. Si no los limpiamos, los gradientes de la época anterior se suman a los nuevos. Es el error más común de principiantes.
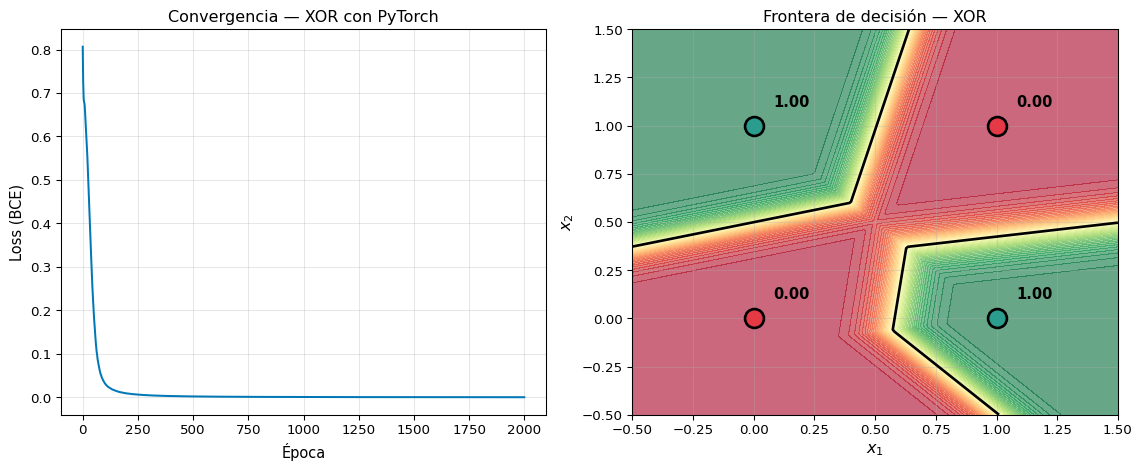
Ejemplo: MLP para XOR con PyTorch
Code
# XOR con PyTorch — comparar con la versión NumPy de S1X_xor = torch.tensor([[0,0], [0,1], [1,0], [1,1]], dtype=torch.float32)y_xor = torch.tensor([[0], [1], [1], [0]], dtype=torch.float32)# Modelotorch.manual_seed(42)modelo_xor = nn.Sequential( nn.Linear(2, 4), nn.ReLU(), nn.Linear(4, 1),)criterio = nn.BCEWithLogitsLoss()optimizador = torch.optim.Adam(modelo_xor.parameters(), lr=0.05)# Entrenarlosses = []for epoca inrange(2000): logits = modelo_xor(X_xor) loss = criterio(logits, y_xor) optimizador.zero_grad() loss.backward() optimizador.step() losses.append(loss.item())# Prediccioneswith torch.no_grad(): preds = torch.sigmoid(modelo_xor(X_xor))print("XOR con PyTorch:")for i inrange(4):print(f" [{int(X_xor[i][0])}, {int(X_xor[i][1])}] → {preds[i].item():.4f} "f"(esperado: {int(y_xor[i])})")print(f"\nLoss final: {losses[-1]:.6f}")print(f"Líneas de código vs NumPy: ~15 vs ~30 😎")
XOR con PyTorch:
[0, 0] → 0.0000 (esperado: 0)
[0, 1] → 1.0000 (esperado: 1)
[1, 0] → 0.9994 (esperado: 1)
[1, 1] → 0.0000 (esperado: 0)
Loss final: 0.000174
Líneas de código vs NumPy: ~15 vs ~30 😎
flowchart LR subgraph Datos ["Datos"] T["Textos y Etiquetas"] end subgraph Vectorizar ["Vectorización"] E["TF-IDF / Embeddings"] end subgraph Modelo ["Modelo"] M["MLP nn.Module"] end subgraph Entrenar ["Entrenar"] L["Loss, Optim, Backprop"] end subgraph Evaluar ["Evaluar"] R["Accuracy, F1, Reporte"] end T --> E --> M --> L --> R style Datos fill:#cfe2ff style Vectorizar fill:#90e0ef style Modelo fill:#00b4d8,color:#fff style Entrenar fill:#0077b6,color:#fff style Evaluar fill:#023e8a,color:#fff
flowchart LR
subgraph Datos ["Datos"]
T["Textos y Etiquetas"]
end
subgraph Vectorizar ["Vectorización"]
E["TF-IDF / Embeddings"]
end
subgraph Modelo ["Modelo"]
M["MLP nn.Module"]
end
subgraph Entrenar ["Entrenar"]
L["Loss, Optim, Backprop"]
end
subgraph Evaluar ["Evaluar"]
R["Accuracy, F1, Reporte"]
end
T --> E --> M --> L --> R
style Datos fill:#cfe2ff
style Vectorizar fill:#90e0ef
style Modelo fill:#00b4d8,color:#fff
style Entrenar fill:#0077b6,color:#fff
style Evaluar fill:#023e8a,color:#fff
Hoy implementamos cada paso con datos reales y PyTorch.
Paso 1: Preparar los Datos
Code
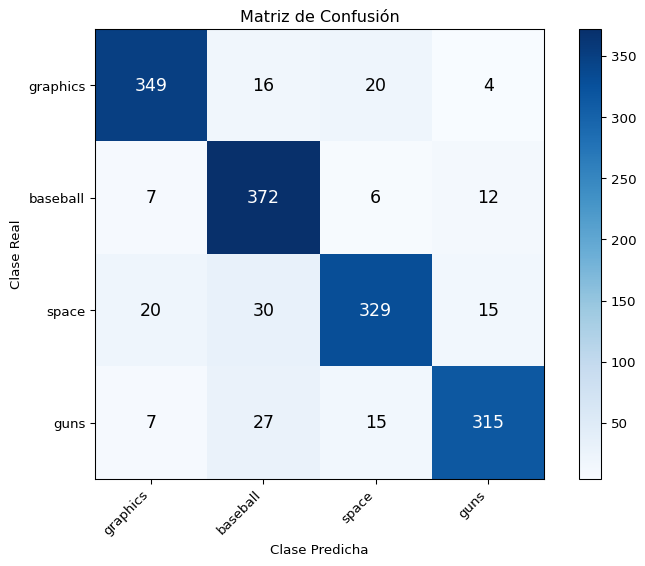
from sklearn.datasets import fetch_20newsgroupsfrom sklearn.feature_extraction.text import TfidfVectorizerfrom sklearn.model_selection import train_test_splitfrom sklearn.preprocessing import LabelEncoderimport warningswarnings.filterwarnings('ignore')# Usar 4 categorías para simplificarcategorias = ['sci.space', 'rec.sport.baseball', 'talk.politics.guns', 'comp.graphics']datos_train = fetch_20newsgroups(subset='train', categories=categorias, remove=('headers', 'footers', 'quotes'))datos_test = fetch_20newsgroups(subset='test', categories=categorias, remove=('headers', 'footers', 'quotes'))print(f"Documentos de entrenamiento: {len(datos_train.data)}")print(f"Documentos de test: {len(datos_test.data)}")print(f"\nCategorías ({len(categorias)}):")for i, cat inenumerate(datos_train.target_names): n =sum(datos_train.target == i)print(f" {i}: {cat} ({n} docs)")
Durante el entrenamiento, apaga aleatoriamente el 30% de las neuronas en cada paso. Esto obliga a la red a no depender de ninguna neurona individual → mejor generalización. En evaluación se desactiva automáticamente.
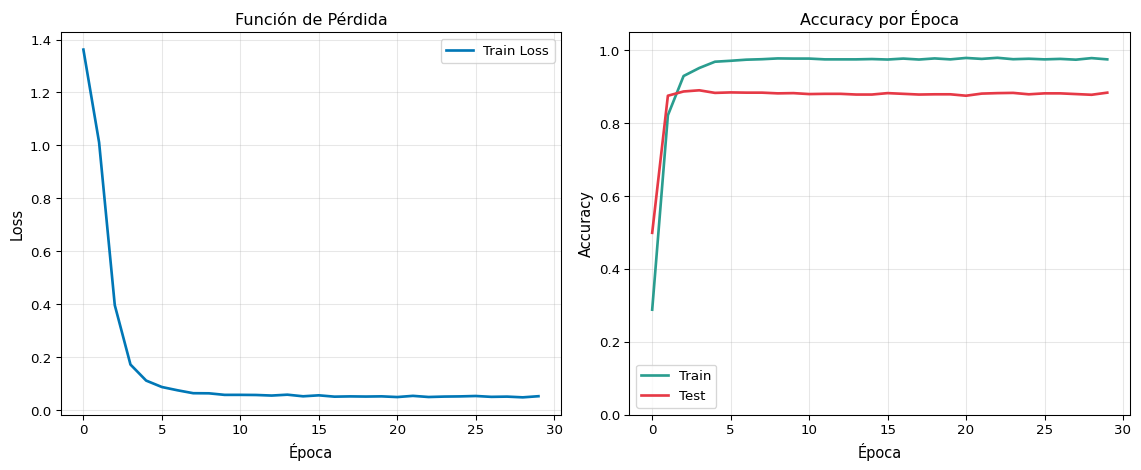
Paso 4: Entrenar
Code
from torch.utils.data import DataLoader, TensorDataset# Dataset y DataLoadertrain_dataset = TensorDataset(X_train_t, y_train_t)train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True)# Pérdida y optimizadorcriterio = nn.CrossEntropyLoss()optimizador = torch.optim.Adam(modelo.parameters(), lr=0.001)# Entrenamientonum_epocas =30historial = {'train_loss': [], 'train_acc': [], 'test_acc': []}for epoca inrange(num_epocas): modelo.train() epoch_loss =0 correctos =0 total =0for X_batch, y_batch in train_loader:# Forward logits = modelo(X_batch) loss = criterio(logits, y_batch)# Backward optimizador.zero_grad() loss.backward() optimizador.step() epoch_loss += loss.item() *len(y_batch) correctos += (logits.argmax(dim=1) == y_batch).sum().item() total +=len(y_batch)# Métricas de la época train_loss = epoch_loss / total train_acc = correctos / total# Evaluación en test modelo.eval()with torch.no_grad(): logits_test = modelo(X_test_t) test_acc = (logits_test.argmax(dim=1) == y_test_t).float().mean().item() historial['train_loss'].append(train_loss) historial['train_acc'].append(train_acc) historial['test_acc'].append(test_acc)if (epoca +1) %10==0:print(f"Época {epoca+1:3d}/{num_epocas} | "f"Loss: {train_loss:.4f} | "f"Train Acc: {train_acc:.1%} | "f"Test Acc: {test_acc:.1%}")
Época 10/30 | Loss: 0.0579 | Train Acc: 97.8% | Test Acc: 88.3%
Época 20/30 | Loss: 0.0523 | Train Acc: 97.5% | Test Acc: 88.0%
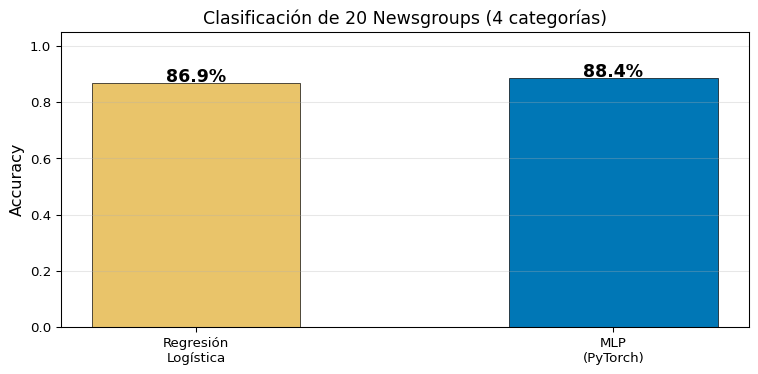
Época 30/30 | Loss: 0.0528 | Train Acc: 97.5% | Test Acc: 88.4%
Con TF-IDF como input, la regresión logística es un baseline muy fuerte. Las redes neuronales brillan más cuando aprenden sus propias representaciones (embeddings entrenables), algo que veremos con modelos más avanzados.
Bloque 7: Resumen
Lo Que Aprendimos Hoy
PyTorch
Tensores con autograd automático
nn.Module para definir arquitecturas
DataLoader para mini-batches
Loop: forward → loss → zero_grad → backward → step
Clasificación de texto
Pipeline: TF-IDF → MLP → CrossEntropy
Dropout para regularización
Adam como optimizador por defecto
F1 como métrica principal (no solo accuracy)
Siempre comparar con un baseline simple
Fórmulas Clave
Concepto
Fórmula
Cross-Entropy
\(\mathcal{L} = -\sum_c y_c \log \hat{y}_c\)
Softmax
\(\hat{y}_c = \frac{e^{z_c}}{\sum_k e^{z_k}}\)
Dropout
\(h_i = h_i \cdot m_i\), donde \(m_i \sim \text{Bernoulli}(1-p)\)
Adam
\(w \leftarrow w - \eta \frac{\hat{m}_t}{\sqrt{\hat{v}_t} + \epsilon}\)
Precision
\(P = \frac{TP}{TP + FP}\)
Recall
\(R = \frac{TP}{TP + FN}\)
F1
\(F_1 = 2 \cdot \frac{P \cdot R}{P + R}\)
Para la Próxima Sesión 📚
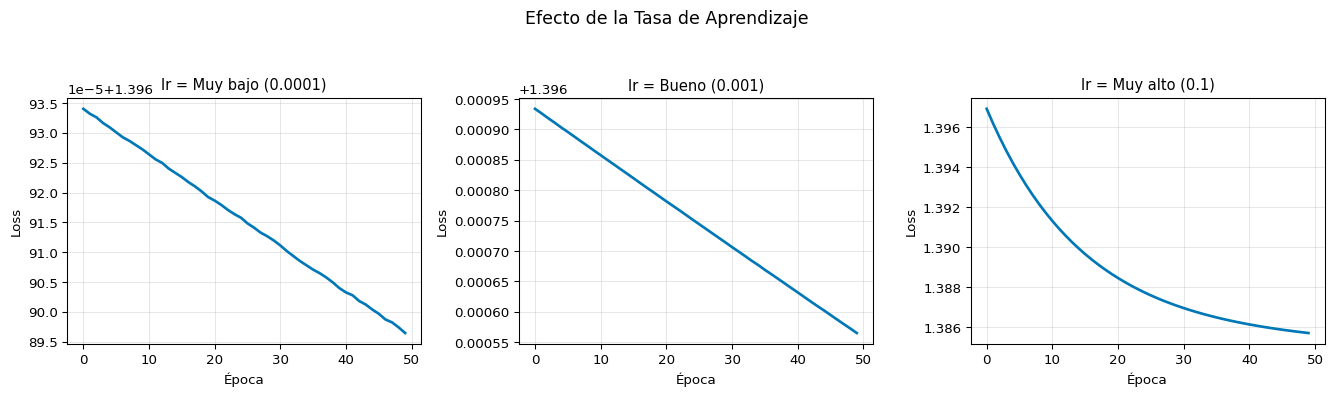
S3: Variantes de Descenso de Gradiente y Regularización