Code
flowchart LR
x1["x₁"] -->|w₁| S["Σ + b"]
x2["x₂"] -->|w₂| S
x3["x₃"] -->|w₃| S
S --> F["f(z)"]
F --> Y["ŷ"]
style S fill:#0077b6,color:#fff
style F fill:#e63946,color:#fff
style Y fill:#2a9d8f,color:#fff
S1: Repaso de Perceptrones y Retropropagación
2026-03-10
import numpy as np
import matplotlib.pyplot as plt
np.random.seed(42)
# Datos linealmente separables: ¿sentimiento positivo o negativo?
# Simulamos: x1 = frecuencia de palabras positivas, x2 = frecuencia de palabras negativas
n = 50
positivos = np.random.randn(n, 2) + [2, 0] # cluster positivo
negativos = np.random.randn(n, 2) + [0, 2] # cluster negativo
X = np.vstack([positivos, negativos])
y = np.array([1]*n + [0]*n)
# Perceptrón desde cero
w = np.zeros(2)
b = 0.0
eta = 0.1
errores_por_epoca = []
for epoca in range(20):
errores = 0
for i in range(len(X)):
z = np.dot(w, X[i]) + b
y_hat = 1 if z >= 0 else 0
error = y[i] - y_hat
w += eta * error * X[i]
b += eta * error
if error != 0:
errores += 1
errores_por_epoca.append(errores)
fig, axes = plt.subplots(1, 2, figsize=(12, 5))
# Frontera de decisión
ax = axes[0]
ax.scatter(positivos[:, 0], positivos[:, 1], c='#2a9d8f', label='Positivo', s=40, alpha=0.7)
ax.scatter(negativos[:, 0], negativos[:, 1], c='#e63946', label='Negativo', s=40, alpha=0.7)
x_line = np.linspace(-2, 5, 100)
if w[1] != 0:
y_line = -(w[0] * x_line + b) / w[1]
ax.plot(x_line, y_line, 'k--', linewidth=2, label='Frontera')
ax.set_xlabel('Frecuencia palabras positivas', fontsize=11)
ax.set_ylabel('Frecuencia palabras negativas', fontsize=11)
ax.set_title('Perceptrón: Clasificación de Sentimiento', fontsize=12)
ax.legend(fontsize=10)
ax.grid(True, alpha=0.3)
ax.set_xlim(-2, 5)
ax.set_ylim(-2, 5)
# Convergencia
ax = axes[1]
ax.plot(range(1, 21), errores_por_epoca, 'o-', color='#0077b6', markersize=5)
ax.set_xlabel('Época', fontsize=11)
ax.set_ylabel('Errores', fontsize=11)
ax.set_title('Convergencia del Perceptrón', fontsize=12)
ax.grid(True, alpha=0.3)
plt.tight_layout()
plt.show()
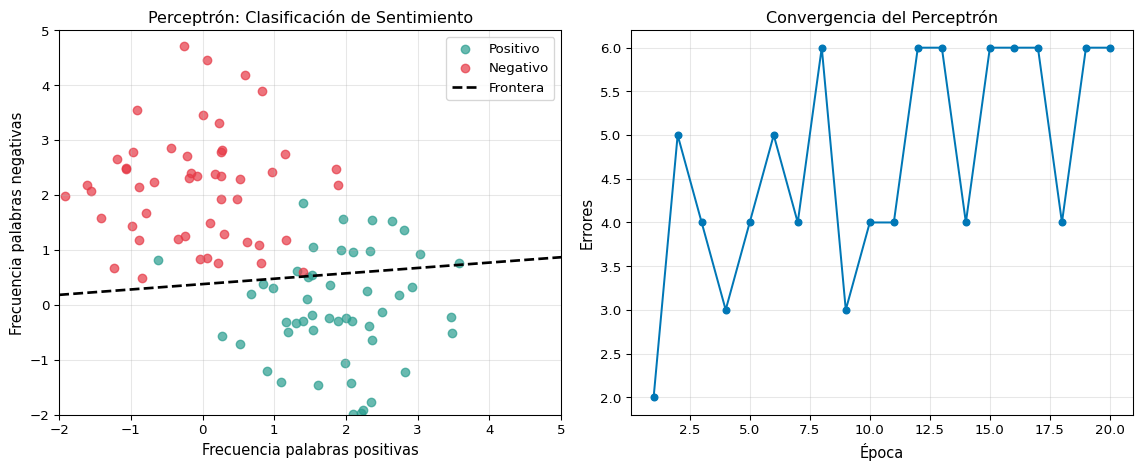
print(f"Pesos finales: w = [{w[0]:.3f}, {w[1]:.3f}], b = {b:.3f}")
print(f"Errores finales: {errores_por_epoca[-1]}")Pesos finales: w = [0.052, -0.529], b = 0.200
Errores finales: 6fig, axes = plt.subplots(1, 3, figsize=(14, 4))
gates = {
'AND': ([0,0,1,1], [0,1,0,1], [0,0,0,1]),
'OR': ([0,0,1,1], [0,1,0,1], [0,1,1,1]),
'XOR': ([0,0,1,1], [0,1,0,1], [0,1,1,0]),
}
colores_gate = {0: '#e63946', 1: '#2a9d8f'}
for ax, (nombre, (x1, x2, y_gate)) in zip(axes, gates.items()):
for i in range(4):
ax.scatter(x1[i], x2[i], c=colores_gate[y_gate[i]],
s=200, zorder=5, edgecolors='black', linewidth=1.5)
ax.annotate(str(y_gate[i]), (x1[i], x2[i]),
fontsize=14, fontweight='bold', ha='center', va='center',
color='white')
if nombre != 'XOR':
xx = np.linspace(-0.5, 1.5, 100)
if nombre == 'AND':
yy = 1.5 - xx # w1=1, w2=1, b=-1.5
else:
yy = 0.5 - xx # w1=1, w2=1, b=-0.5
ax.plot(xx, yy, 'k--', linewidth=2, alpha=0.7)
ax.fill_between(xx, yy, 2, alpha=0.05, color='#2a9d8f')
else:
ax.text(0.5, -0.3, '¿Dónde va la línea?', ha='center',
fontsize=11, style='italic', color='#e63946')
ax.set_xlim(-0.5, 1.5)
ax.set_ylim(-0.5, 1.5)
ax.set_xlabel('$x_1$', fontsize=12)
ax.set_ylabel('$x_2$', fontsize=12)
ax.set_title(nombre, fontsize=14, fontweight='bold')
ax.grid(True, alpha=0.3)
ax.set_aspect('equal')
plt.tight_layout()
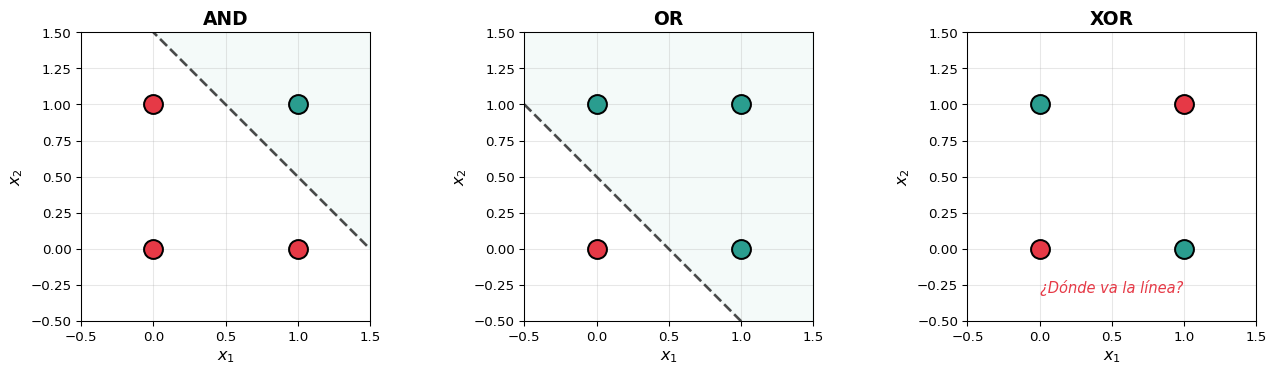
plt.show()La Crisis del Perceptrón (Minsky & Papert, 1969)
Demostraron que un perceptrón no puede resolver XOR y que las limitaciones lineales son fundamentales. Esto causó el primer “invierno” de la IA (~1970-1986).
La solución: apilar perceptrones en múltiples capas → redes neuronales profundas.
x = np.linspace(-4, 4, 200)
# Funciones de activación
sigmoid = 1 / (1 + np.exp(-x))
tanh_vals = np.tanh(x)
relu = np.maximum(0, x)
leaky_relu = np.where(x > 0, x, 0.01 * x)
fig, axes = plt.subplots(2, 2, figsize=(12, 8))
configs = [
(axes[0,0], sigmoid, 'Sigmoide: $\\sigma(z) = \\frac{1}{1+e^{-z}}$', '#0077b6'),
(axes[0,1], tanh_vals, 'Tanh: $\\tanh(z) = \\frac{e^z - e^{-z}}{e^z + e^{-z}}$', '#2a9d8f'),
(axes[1,0], relu, 'ReLU: $\\max(0, z)$', '#e63946'),
(axes[1,1], leaky_relu, 'Leaky ReLU: $\\max(0.01z, z)$', '#e9c46a'),
]
for ax, y_vals, titulo, color in configs:
ax.plot(x, y_vals, linewidth=2.5, color=color)
ax.axhline(y=0, color='gray', linewidth=0.5)
ax.axvline(x=0, color='gray', linewidth=0.5)
ax.set_title(titulo, fontsize=12)
ax.grid(True, alpha=0.3)
ax.set_xlabel('z', fontsize=11)
ax.set_ylabel('f(z)', fontsize=11)
plt.tight_layout()
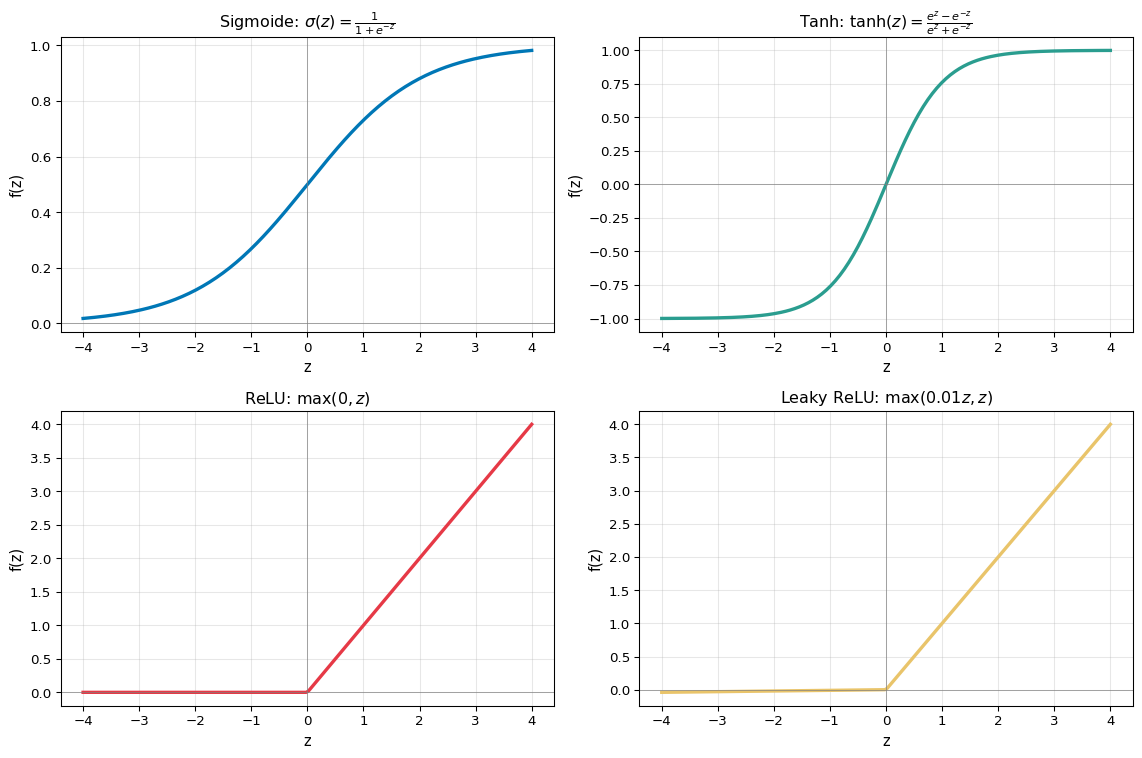
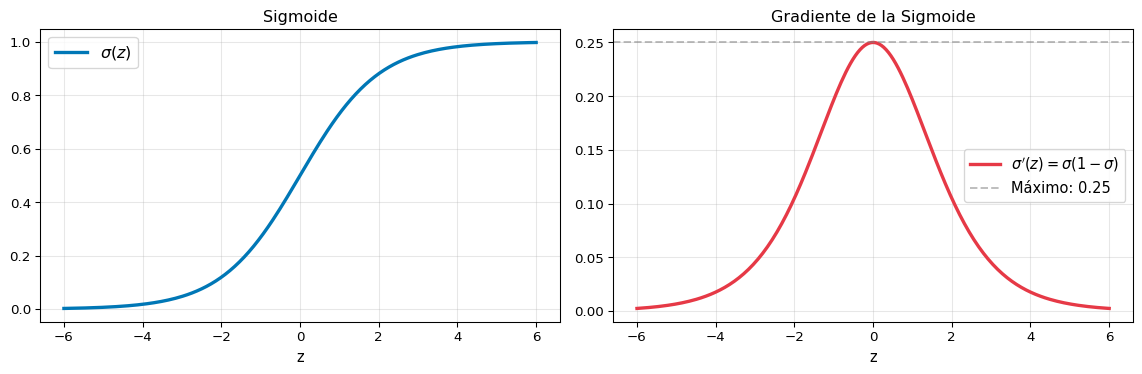
plt.show()¿Por qué la sigmoide causa “gradientes que desaparecen”?
x = np.linspace(-6, 6, 200)
sig = 1 / (1 + np.exp(-x))
sig_grad = sig * (1 - sig)
fig, axes = plt.subplots(1, 2, figsize=(12, 4))
ax = axes[0]
ax.plot(x, sig, linewidth=2.5, color='#0077b6', label='$\\sigma(z)$')
ax.set_title('Sigmoide', fontsize=12)
ax.legend(fontsize=12)
ax.grid(True, alpha=0.3)
ax.set_xlabel('z', fontsize=11)
ax = axes[1]
ax.plot(x, sig_grad, linewidth=2.5, color='#e63946', label="$\\sigma'(z) = \\sigma(1-\\sigma)$")
ax.axhline(y=0.25, color='gray', linestyle='--', alpha=0.5, label='Máximo: 0.25')
ax.set_title('Gradiente de la Sigmoide', fontsize=12)
ax.legend(fontsize=11)
ax.grid(True, alpha=0.3)
ax.set_xlabel('z', fontsize=11)
plt.tight_layout()
plt.show()Problema de saturación
Cuando \(|z|\) es grande, \(\sigma'(z) \approx 0\). En una red profunda, multiplicar muchos gradientes pequeños (\(< 0.25\)) → el gradiente se desvanece exponencialmente en las capas más tempranas.
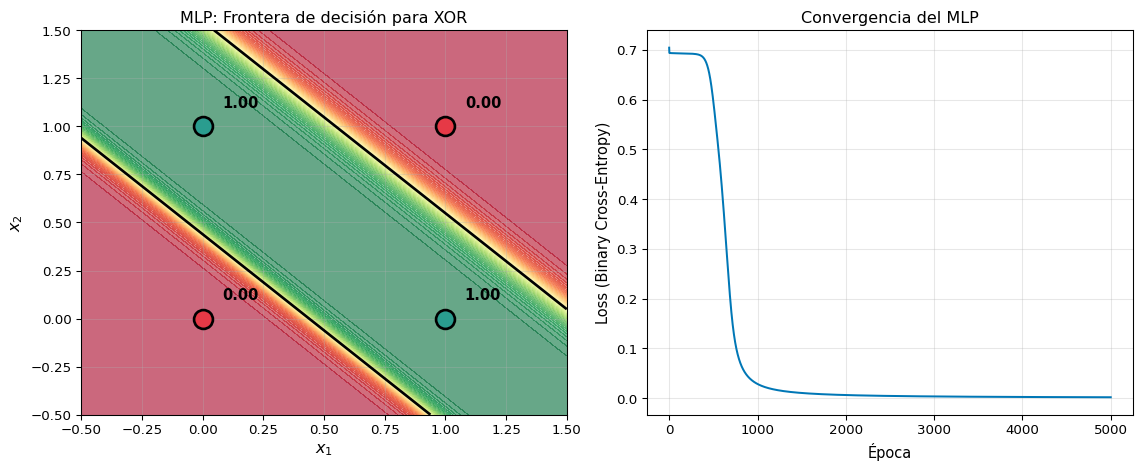
# MLP para XOR — desde cero con NumPy
X_xor = np.array([[0,0], [0,1], [1,0], [1,1]])
y_xor = np.array([[0], [1], [1], [0]])
np.random.seed(42)
# Arquitectura: 2 → 4 → 1
W1 = np.random.randn(2, 4) * 0.5
b1 = np.zeros((1, 4))
W2 = np.random.randn(4, 1) * 0.5
b2 = np.zeros((1, 1))
def sigmoid(z):
return 1 / (1 + np.exp(-z))
eta = 1.0
losses = []
for epoca in range(5000):
# Forward
z1 = X_xor @ W1 + b1
h1 = sigmoid(z1)
z2 = h1 @ W2 + b2
y_hat = sigmoid(z2)
# Loss (binary cross-entropy)
loss = -np.mean(y_xor * np.log(y_hat + 1e-8) + (1 - y_xor) * np.log(1 - y_hat + 1e-8))
losses.append(loss)
# Backward
dz2 = y_hat - y_xor # (4, 1)
dW2 = h1.T @ dz2 / 4 # (4, 1)
db2 = np.mean(dz2, axis=0, keepdims=True) # (1, 1)
dh1 = dz2 @ W2.T # (4, 4)
dz1 = dh1 * h1 * (1 - h1) # (4, 4)
dW1 = X_xor.T @ dz1 / 4 # (2, 4)
db1 = np.mean(dz1, axis=0, keepdims=True) # (1, 4)
# Update
W2 -= eta * dW2
b2 -= eta * db2
W1 -= eta * dW1
b1 -= eta * db1
# Resultados
fig, axes = plt.subplots(1, 2, figsize=(12, 5))
# Frontera de decisión
ax = axes[0]
xx, yy = np.meshgrid(np.linspace(-0.5, 1.5, 200), np.linspace(-0.5, 1.5, 200))
grid = np.c_[xx.ravel(), yy.ravel()]
h_grid = sigmoid(grid @ W1 + b1)
z_grid = sigmoid(h_grid @ W2 + b2).reshape(xx.shape)
ax.contourf(xx, yy, z_grid, levels=50, cmap='RdYlGn', alpha=0.6)
ax.contour(xx, yy, z_grid, levels=[0.5], colors='black', linewidths=2)
for i in range(4):
color = '#2a9d8f' if y_xor[i][0] == 1 else '#e63946'
ax.scatter(X_xor[i, 0], X_xor[i, 1], c=color, s=200,
edgecolors='black', linewidth=2, zorder=5)
ax.annotate(f'{y_hat[i][0]:.2f}', (X_xor[i,0]+0.08, X_xor[i,1]+0.1),
fontsize=11, fontweight='bold')
ax.set_xlabel('$x_1$', fontsize=12)
ax.set_ylabel('$x_2$', fontsize=12)
ax.set_title('MLP: Frontera de decisión para XOR', fontsize=12)
ax.grid(True, alpha=0.3)
# Convergencia
ax = axes[1]
ax.plot(losses, color='#0077b6', linewidth=1.5)
ax.set_xlabel('Época', fontsize=11)
ax.set_ylabel('Loss (Binary Cross-Entropy)', fontsize=11)
ax.set_title('Convergencia del MLP', fontsize=12)
ax.grid(True, alpha=0.3)
plt.tight_layout()
plt.show()
print(f"Predicciones finales:")
for i in range(4):
print(f" x={X_xor[i]} → ŷ={y_hat[i][0]:.4f} (esperado: {y_xor[i][0]})")Predicciones finales:
x=[0 0] → ŷ=0.0024 (esperado: 0)
x=[0 1] → ŷ=0.9984 (esperado: 1)
x=[1 0] → ŷ=0.9984 (esperado: 1)
x=[1 1] → ŷ=0.0013 (esperado: 0)Lección clave
La frontera de decisión del MLP es no lineal — puede separar las clases de XOR. Cada capa oculta transforma el espacio de entrada en un espacio donde los datos sí son linealmente separables.
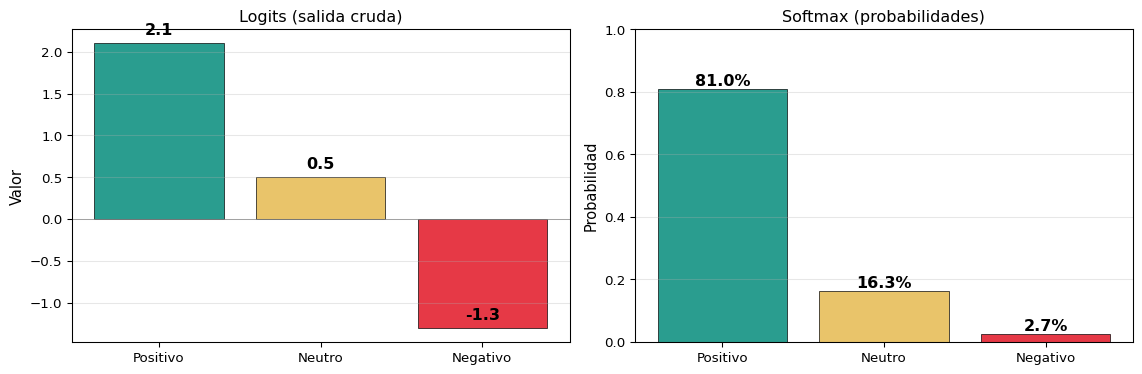
# Ejemplo: clasificación de sentimiento en 3 clases
logits = np.array([2.1, 0.5, -1.3]) # salida de la última capa
clases = ['Positivo', 'Neutro', 'Negativo']
# Softmax
exp_logits = np.exp(logits - np.max(logits)) # truco de estabilidad numérica
softmax_probs = exp_logits / exp_logits.sum()
fig, axes = plt.subplots(1, 2, figsize=(12, 4))
# Logits (valores crudos)
ax = axes[0]
colors = ['#2a9d8f', '#e9c46a', '#e63946']
bars = ax.bar(clases, logits, color=colors, edgecolor='black', linewidth=0.5)
for bar, val in zip(bars, logits):
ax.text(bar.get_x() + bar.get_width()/2., bar.get_height() + 0.1,
f'{val:.1f}', ha='center', fontweight='bold', fontsize=12)
ax.set_title('Logits (salida cruda)', fontsize=12)
ax.set_ylabel('Valor', fontsize=11)
ax.axhline(y=0, color='gray', linewidth=0.5)
ax.grid(True, alpha=0.3, axis='y')
# Softmax
ax = axes[1]
bars = ax.bar(clases, softmax_probs, color=colors, edgecolor='black', linewidth=0.5)
for bar, val in zip(bars, softmax_probs):
ax.text(bar.get_x() + bar.get_width()/2., bar.get_height() + 0.01,
f'{val:.1%}', ha='center', fontweight='bold', fontsize=12)
ax.set_title('Softmax (probabilidades)', fontsize=12)
ax.set_ylabel('Probabilidad', fontsize=11)
ax.set_ylim(0, 1)
ax.grid(True, alpha=0.3, axis='y')
plt.tight_layout()
plt.show()
print(f"Logits: {logits} → Softmax: [{', '.join(f'{p:.4f}' for p in softmax_probs)}]")
print(f"Suma de probabilidades: {softmax_probs.sum():.4f}")Logits: [ 2.1 0.5 -1.3] → Softmax: [0.8095, 0.1634, 0.0270]
Suma de probabilidades: 1.0000