La perplejidad mide qué tan “sorprendido” está el modelo al ver el texto de prueba.
Intuición: ¿Qué Significa la Perplejidad?
Como “factor de ramificación”
La perplejidad es el número promedio de palabras entre las cuales el modelo “duda” en cada paso.
PP = 1 → El modelo sabe exactamente qué palabra sigue
PP = 10 → El modelo duda entre 10 opciones en promedio
PP = 50,000 → Equivalente a elegir al azar del vocabulario
Ejemplo visual
Code
graph TD A["El"] --> B["gato"] A --> C["perro"] A --> D["..."] B --> E["come"] B --> F["duerme"] B --> G["..."] style A fill:#0077b6,color:#fff style B fill:#90e0ef,color:#000 style E fill:#cfe2ff,color:#000 style C fill:#e0e0e0,color:#888 style D fill:#e0e0e0,color:#888 style F fill:#e0e0e0,color:#888 style G fill:#e0e0e0,color:#888
graph TD
A["El"] --> B["gato"]
A --> C["perro"]
A --> D["..."]
B --> E["come"]
B --> F["duerme"]
B --> G["..."]
style A fill:#0077b6,color:#fff
style B fill:#90e0ef,color:#000
style E fill:#cfe2ff,color:#000
style C fill:#e0e0e0,color:#888
style D fill:#e0e0e0,color:#888
style F fill:#e0e0e0,color:#888
style G fill:#e0e0e0,color:#888
Si PP = 2, en promedio el modelo duda entre 2 opciones.
Ejemplo Numérico
Corpus de test: “el gato come” (3 palabras, usando bigrama)
# Comparar unigrama vs bigramadef perplejidad_unigrama(conteos_unigrama, total_palabras, texto_test, V):"""Perplejidad de un modelo unigrama.""" palabras = texto_test.split() N =len(palabras) log_prob =0.0for w in palabras: conteo = conteos_unigrama.get(w, 0)if conteo >0: prob = conteo / total_palabraselse: prob =1/ V log_prob += np.log2(prob)return2** (-log_prob / N)total_palabras =sum(conteos_unigrama[w] for w in conteos_unigrama if w notin ['<s>', '</s>'])print("Comparación Unigrama vs Bigrama:")print("-"*55)print(f"{'Texto':<35}{'Unigrama':>8}{'Bigrama':>8}")print("-"*55)for test in [test1, test2, test3]: pp_uni = perplejidad_unigrama(conteos_unigrama, total_palabras, test, V) pp_bi = calcular_perplejidad(conteos_bigrama, conteos_unigrama, test, V)print(f"{test:<35}{pp_uni:>8.2f}{pp_bi:>8.2f}")
Comparación Unigrama vs Bigrama:
-------------------------------------------------------
Texto Unigrama Bigrama
-------------------------------------------------------
el gato come pescado 8.00 1.52
el gato come carne 8.00 1.52
el elefante baila salsa 8.54 6.81
Observación
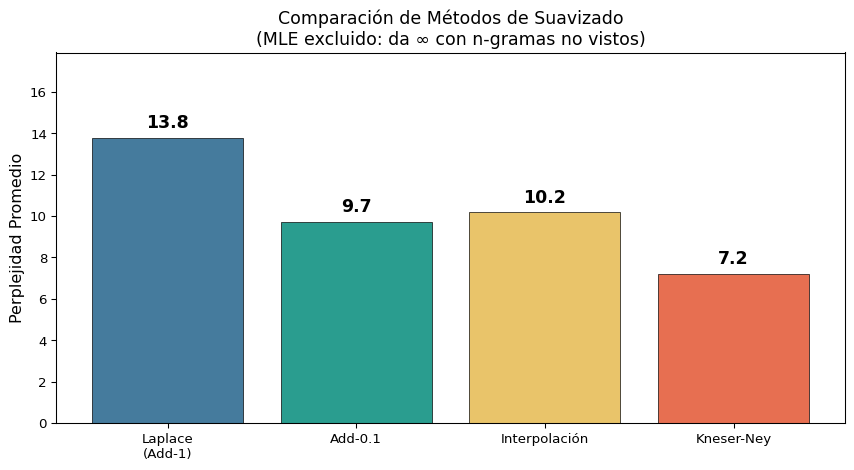
El modelo de bigrama tiene menor perplejidad en oraciones que siguen patrones del corpus de entrenamiento. Pero ¿qué pasa con palabras o combinaciones nunca vistas?
Bloque 4: El Problema de las Probabilidades Cero
El Desastre del Cero
El problema
Si un bigrama nunca aparece en el corpus de entrenamiento:
\(k\) se puede optimizar en un conjunto de validación
Desventaja
Sigue siendo una heurística simple
No aprovecha información de los unigramas
Code
# Efecto de k en las probabilidadesprint("Efecto del valor de k en P(pescado|come):")print("-"*40)for k in [0.001, 0.01, 0.1, 0.5, 1.0]: p = bigrama_laplace(conteos_bigrama, conteos_unigrama, ("come", "pescado"), V, k=k)print(f" k = {k:<6} → P = {p:.4f}")
Efecto del valor de k en P(pescado|come):
----------------------------------------
k = 0.001 → P = 0.4978
k = 0.01 → P = 0.4787
k = 0.1 → P = 0.3548
k = 0.5 → P = 0.2000
k = 1.0 → P = 0.1538
5.3 Interpolación Lineal
Idea: Combinar modelos de diferentes órdenes \(n\)-gram.
Idea: Usar el modelo de mayor orden si hay datos suficientes. Si no, retroceder al modelo de menor orden.
Algoritmo
Si C(w_{i-2}, w_{i-1}, w_i) > 0:
usar P_trigrama
Si no, si C(w_{i-1}, w_i) > 0:
usar α × P_bigrama ← descuento
Si no:
usar α × β × P_unigrama ← doble descuento
Code
graph TD A["¿Trigrama visto?"] -->|Sí| B["Usar P_trigrama"] A -->|No| C["¿Bigrama visto?"] C -->|Sí| D["Usar α·P_bigrama"] C -->|No| E["Usar α·β·P_unigrama"] style A fill:#0077b6,color:#fff style B fill:#00b4d8,color:#fff style C fill:#0077b6,color:#fff style D fill:#90e0ef,color:#000 style E fill:#cfe2ff,color:#000
graph TD
A["¿Trigrama visto?"] -->|Sí| B["Usar P_trigrama"]
A -->|No| C["¿Bigrama visto?"]
C -->|Sí| D["Usar α·P_bigrama"]
C -->|No| E["Usar α·β·P_unigrama"]
style A fill:#0077b6,color:#fff
style B fill:#00b4d8,color:#fff
style C fill:#0077b6,color:#fff
style D fill:#90e0ef,color:#000
style E fill:#cfe2ff,color:#000
Diferencia con Interpolación
Interpolación: Siempre combina todos los niveles
Backoff: Solo usa niveles inferiores cuando el superior falla
5.5 Suavizado de Kneser-Ney
El método más sofisticado y efectivo para n-gramas. Se basa en dos ideas clave:
Idea 1: Descuento Absoluto
En lugar de redistribuir proporcionalmente, restar una constante\(d\) (típicamente \(d \approx 0.75\)):