import re
import spacy
from nltk.corpus import stopwords
import nltk
nltk.download('stopwords', quiet=True)
nlp = spacy.load("es_core_news_sm")
stops = set(stopwords.words('spanish'))
def preprocesar(texto, usar_lemas=True, quitar_stops=True):
"""Pipeline de preprocesamiento (Semana 1)."""
texto = texto.lower()
texto = re.sub(r"[^\w\sáéíóúñü]", " ", texto)
texto = re.sub(r"\s+", " ", texto).strip()
doc = nlp(texto)
tokens = []
for token in doc:
palabra = token.lemma_ if usar_lemas else token.text
if quitar_stops and palabra in stops:
continue
if not palabra.isalpha():
continue
tokens.append(palabra)
return tokensSemántica Léxica & Espacio Vectorial
S1: Bolsa de Palabras (BoW) y One-hot Encoding
Prof. Francisco Suárez
Universidad Católica Boliviana
2026-04-15
Agenda de Hoy
Primera Parte
- 🔢 ¿Por qué representar texto como números?
- 🎯 One-hot Encoding
- 📐 Vectores y Espacio Vectorial
Segunda Parte
- 🎒 Modelo Bag of Words (BoW)
- 📊 Matriz Documento-Término
- 🔍 Similitud entre documentos
Bloque 1: Del Texto a los Números
Recordemos: Preprocesamiento
La semana pasada aprendimos a limpiar y tokenizar texto:
El Problema Fundamental
Lo que nosotros vemos 👀
Entendemos que ambos hablan de animales domésticos haciendo actividades cotidianas.
Pregunta Clave
¿Cómo convertimos texto en representaciones numéricas que capturen su significado?
Representación Vectorial del Texto
Code
flowchart LR
A[📄 Texto<br>crudo] --> B[🧹 Pre-<br>procesamiento]
B --> C[🔢 Representación<br>Numérica]
C --> D[🤖 Modelo<br>ML/DL]
D --> E[📈 Predicción]
style A fill:#fff3cd,color:#000
style B fill:#cfe2ff,color:#000
style C fill:#d4edda,color:#000,stroke:#28a745,stroke-width:3px
style D fill:#e2d9f3,color:#000
style E fill:#f8d7da,color:#000flowchart LR
A[📄 Texto<br>crudo] --> B[🧹 Pre-<br>procesamiento]
B --> C[🔢 Representación<br>Numérica]
C --> D[🤖 Modelo<br>ML/DL]
D --> E[📈 Predicción]
style A fill:#fff3cd,color:#000
style B fill:#cfe2ff,color:#000
style C fill:#d4edda,color:#000,stroke:#28a745,stroke-width:3px
style D fill:#e2d9f3,color:#000
style E fill:#f8d7da,color:#000
Hoy aprenderemos las primeras técnicas para el paso Representación Numérica:
| Técnica | Nivel | Captura |
|---|---|---|
| One-hot Encoding | Palabra | Identidad |
| Bag of Words | Documento | Frecuencia |
Bloque 2: One-hot Encoding
¿Qué es One-hot Encoding?
Representar cada palabra como un vector binario donde una sola posición es 1 y el resto son 0.
Implementación Manual
import numpy as np
# Definir vocabulario
oracion = "el gato come pescado y el perro come carne"
palabras = oracion.split()
vocabulario = sorted(set(palabras))
print(f"Vocabulario ({len(vocabulario)} palabras): {vocabulario}")
# Crear mapeo palabra → índice
palabra_a_idx = {palabra: i for i, palabra in enumerate(vocabulario)}
print(f"\nMapeo: {palabra_a_idx}")
# Crear vectores one-hot
print(f"\nVectores One-hot:")
for palabra in vocabulario:
vector = np.zeros(len(vocabulario), dtype=int)
vector[palabra_a_idx[palabra]] = 1
print(f" '{palabra:10s}' → {vector}")Vocabulario (7 palabras): ['carne', 'come', 'el', 'gato', 'perro', 'pescado', 'y']
Mapeo: {'carne': 0, 'come': 1, 'el': 2, 'gato': 3, 'perro': 4, 'pescado': 5, 'y': 6}
Vectores One-hot:
'carne ' → [1 0 0 0 0 0 0]
'come ' → [0 1 0 0 0 0 0]
'el ' → [0 0 1 0 0 0 0]
'gato ' → [0 0 0 1 0 0 0]
'perro ' → [0 0 0 0 1 0 0]
'pescado ' → [0 0 0 0 0 1 0]
'y ' → [0 0 0 0 0 0 1]Implementación con scikit-learn
from sklearn.preprocessing import LabelEncoder, OneHotEncoder
import numpy as np
# Vocabulario
palabras = ["gato", "perro", "pez", "ave", "gato", "perro"]
# Paso 1: Etiquetar con enteros
label_enc = LabelEncoder()
enteros = label_enc.fit_transform(palabras)
print(f"Palabras: {palabras}")
print(f"Enteros: {list(enteros)}")
# Paso 2: One-hot encoding
onehot_enc = OneHotEncoder(sparse_output=False)
onehot = onehot_enc.fit_transform(enteros.reshape(-1, 1))
print(f"\nOne-hot encoding:")
for palabra, vector in zip(palabras, onehot):
print(f" '{palabra}' → {vector.astype(int)}")Palabras: ['gato', 'perro', 'pez', 'ave', 'gato', 'perro']
Enteros: [np.int64(1), np.int64(2), np.int64(3), np.int64(0), np.int64(1), np.int64(2)]
One-hot encoding:
'gato' → [0 1 0 0]
'perro' → [0 0 1 0]
'pez' → [0 0 0 1]
'ave' → [1 0 0 0]
'gato' → [0 1 0 0]
'perro' → [0 0 1 0]Visualización: Espacio One-hot
Code
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
import numpy as np
fig = plt.figure(figsize=(7, 5))
ax = fig.add_subplot(111, projection='3d')
# Vectores one-hot en 3D (simplificado)
palabras = ["gato", "perro", "pez"]
vectores = np.eye(3)
colores = ['#e63946', '#457b9d', '#2a9d8f']
for palabra, v, color in zip(palabras, vectores, colores):
ax.quiver(0, 0, 0, v[0], v[1], v[2], color=color, arrow_length_ratio=0.1, linewidth=2.5)
ax.text(v[0]*1.1, v[1]*1.1, v[2]*1.1, f' {palabra}', fontsize=13, fontweight='bold', color=color)
ax.set_xlim([0, 1.3])
ax.set_ylim([0, 1.3])
ax.set_zlim([0, 1.3])
ax.set_xlabel('Dim 1', fontsize=10)
ax.set_ylabel('Dim 2', fontsize=10)
ax.set_zlabel('Dim 3', fontsize=10)
ax.set_title('Espacio One-hot (3 palabras)', fontsize=13)
plt.tight_layout()
plt.show()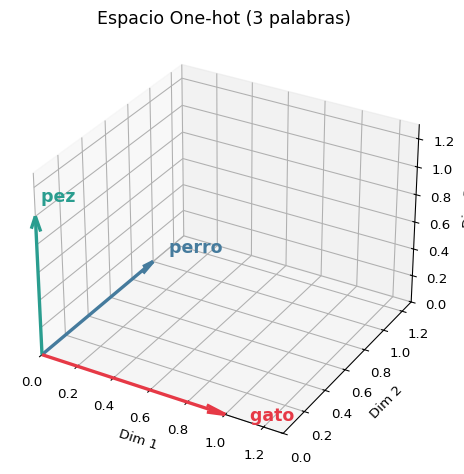
Cada palabra vive en su propio eje: son ortogonales entre sí.
Distancias en One-hot
import numpy as np
from scipy.spatial.distance import cosine, euclidean
# Vectores one-hot
gato = np.array([1, 0, 0, 0, 0])
perro = np.array([0, 1, 0, 0, 0])
mesa = np.array([0, 0, 1, 0, 0])
silla = np.array([0, 0, 0, 1, 0])
felino = np.array([0, 0, 0, 0, 1])
pares = [
("gato", "perro", gato, perro),
("gato", "felino", gato, felino),
("gato", "mesa", gato, mesa),
("mesa", "silla", mesa, silla),
]
print(f"{'Par':<20} {'Dist. Euclídea':<18} {'Dist. Coseno'}")
print("-" * 55)
for n1, n2, v1, v2 in pares:
d_euc = euclidean(v1, v2)
d_cos = cosine(v1, v2)
print(f"{n1+' - '+n2:<20} {d_euc:<18.4f} {d_cos:.4f}")Par Dist. Euclídea Dist. Coseno
-------------------------------------------------------
gato - perro 1.4142 1.0000
gato - felino 1.4142 1.0000
gato - mesa 1.4142 1.0000
mesa - silla 1.4142 1.0000Problema Fundamental
“gato” está igual de lejos de “felino” que de “mesa”. One-hot encoding no captura similitud semántica.
Limitaciones de One-hot Encoding
❌ Problemas
- Alta dimensionalidad
- Vocabulario de 100K palabras = vectores de 100K dimensiones
- Muy disperso (sparse)
- Sin similitud semántica
- Todas las palabras son equidistantes
- “perro” y “gato” tan lejos como “perro” y “galaxia”
- Sin contexto
- “banco” (financiero) = “banco” (sentarse)
✅ Ventajas
- Simple y determinístico
- No necesita entrenamiento
- Útil como entrada para redes neuronales (embedding layer)
- Bueno para variables categóricas no textuales
¿Cuándo usar?
One-hot es el punto de partida. En la práctica, se usa como capa de entrada que luego se transforma en embeddings densos.
Bloque 3: Bag of Words (BoW)
Del Palabra al Documento
One-hot codifica palabras individuales. Pero necesitamos representar documentos completos.
Pregunta:
¿Cómo representamos numéricamente un documento entero?
Bag of Words (Bolsa de Palabras)
Representar un documento como un vector de frecuencias de palabras, ignorando el orden y la gramática.
La Metáfora de la Bolsa 🎒
Code
flowchart LR
A["📄 'El gato come<br>y el perro come'"] --> B["🔤 Tokenizar"]
B --> C["🎒 Meter en<br>la bolsa"]
C --> D["🔢 Contar<br>frecuencias"]
D --> E["📊 Vector<br>[2,1,1,2,1]"]
style A fill:#fff3cd,color:#000
style B fill:#cfe2ff,color:#000
style C fill:#d1e7dd,color:#000
style D fill:#e2d9f3,color:#000
style E fill:#d4edda,color:#000flowchart LR
A["📄 'El gato come<br>y el perro come'"] --> B["🔤 Tokenizar"]
B --> C["🎒 Meter en<br>la bolsa"]
C --> D["🔢 Contar<br>frecuencias"]
D --> E["📊 Vector<br>[2,1,1,2,1]"]
style A fill:#fff3cd,color:#000
style B fill:#cfe2ff,color:#000
style C fill:#d1e7dd,color:#000
style D fill:#e2d9f3,color:#000
style E fill:#d4edda,color:#000
Se pierde el orden:
- ✅ “El gato come pescado” → {el:1, gato:1, come:1, pescado:1}
- ✅ “Come pescado el gato” → {el:1, gato:1, come:1, pescado:1}
Ambas oraciones tienen la misma representación aunque el orden sea diferente.
Ejemplo Paso a Paso
# Corpus de ejemplo
documentos = [
"el gato come pescado",
"el perro come carne",
"el gato y el perro juegan"
]
# Paso 1: Construir vocabulario
vocabulario = sorted(set(
palabra for doc in documentos for palabra in doc.split()
))
print(f"Vocabulario ({len(vocabulario)}): {vocabulario}")
# Paso 2: Crear vectores BoW
print(f"\nVectores Bag of Words:")
print(f"{'Documento':<32} {' '.join(f'{v:>8s}' for v in vocabulario)}")
print("-" * (32 + 9 * len(vocabulario)))
for doc in documentos:
palabras = doc.split()
vector = [palabras.count(v) for v in vocabulario]
print(f"'{doc:<30s}' {' '.join(f'{c:>8d}' for c in vector)}")Vocabulario (8): ['carne', 'come', 'el', 'gato', 'juegan', 'perro', 'pescado', 'y']
Vectores Bag of Words:
Documento carne come el gato juegan perro pescado y
--------------------------------------------------------------------------------------------------------
'el gato come pescado ' 0 1 1 1 0 0 1 0
'el perro come carne ' 1 1 1 0 0 1 0 0
'el gato y el perro juegan ' 0 0 2 1 1 1 0 1Implementación con scikit-learn
from sklearn.feature_extraction.text import CountVectorizer
import pandas as pd
documentos = [
"El gato come pescado fresco",
"El perro come carne roja",
"El gato y el perro juegan juntos",
"El pescado es fresco y rojo"
]
# CountVectorizer crea la representación BoW automáticamente
vectorizer = CountVectorizer()
X = vectorizer.fit_transform(documentos)
# Mostrar como DataFrame
df = pd.DataFrame(
X.toarray(),
columns=vectorizer.get_feature_names_out(),
index=[f"Doc {i+1}" for i in range(len(documentos))]
)
print(df.to_string()) carne come el es fresco gato juegan juntos perro pescado roja rojo
Doc 1 0 1 1 0 1 1 0 0 0 1 0 0
Doc 2 1 1 1 0 0 0 0 0 1 0 1 0
Doc 3 0 0 2 0 0 1 1 1 1 0 0 0
Doc 4 0 0 1 1 1 0 0 0 0 1 0 1La Matriz Documento-Término
La Matriz Documento-Término (DTM) organiza toda la información BoW:
- Filas: documentos
- Columnas: términos del vocabulario
- Valores: frecuencia del término en el documento
\[ M_{ij} = \text{freq}(\text{término}_j, \text{doc}_i) \]
Code
graph TD
A[Corpus<br>N documentos] --> B[Vocabulario<br>V términos]
B --> C["Matriz N × V"]
C --> D[Cada fila =<br>un documento]
C --> E[Cada columna =<br>un término]
style C fill:#0077b6,stroke:#023e8a,color:#fff
Propiedad Importante
La DTM es típicamente muy dispersa (sparse): la mayoría de los valores son 0, porque cada documento usa solo una fracción del vocabulario total.
Visualización de la DTM
Code
import matplotlib.pyplot as plt
import numpy as np
fig, axes = plt.subplots(1, 2, figsize=(12, 4))
# Heatmap de la DTM
im = axes[0].imshow(df.values, cmap='YlOrRd', aspect='auto')
axes[0].set_xticks(range(len(df.columns)))
axes[0].set_xticklabels(df.columns, rotation=45, ha='right', fontsize=9)
axes[0].set_yticks(range(len(df.index)))
axes[0].set_yticklabels(df.index, fontsize=10)
axes[0].set_title('Matriz Documento-Término (DTM)', fontsize=12)
# Anotar valores
for i in range(len(df.index)):
for j in range(len(df.columns)):
axes[0].text(j, i, str(df.values[i, j]), ha='center', va='center', fontsize=10,
color='white' if df.values[i, j] > 0.5 else 'black')
plt.colorbar(im, ax=axes[0], label='Frecuencia')
# Dispersión (sparsity)
total = df.values.size
ceros = (df.values == 0).sum()
no_ceros = total - ceros
axes[1].bar(['Ceros', 'No ceros'], [ceros, no_ceros], color=['#adb5bd', '#0077b6'])
axes[1].set_title(f'Dispersión: {ceros/total*100:.1f}% ceros', fontsize=12)
axes[1].set_ylabel('Cantidad de celdas', fontsize=10)
for i, v in enumerate([ceros, no_ceros]):
axes[1].text(i, v + 0.3, str(v), ha='center', fontsize=12, fontweight='bold')
plt.tight_layout()
plt.show()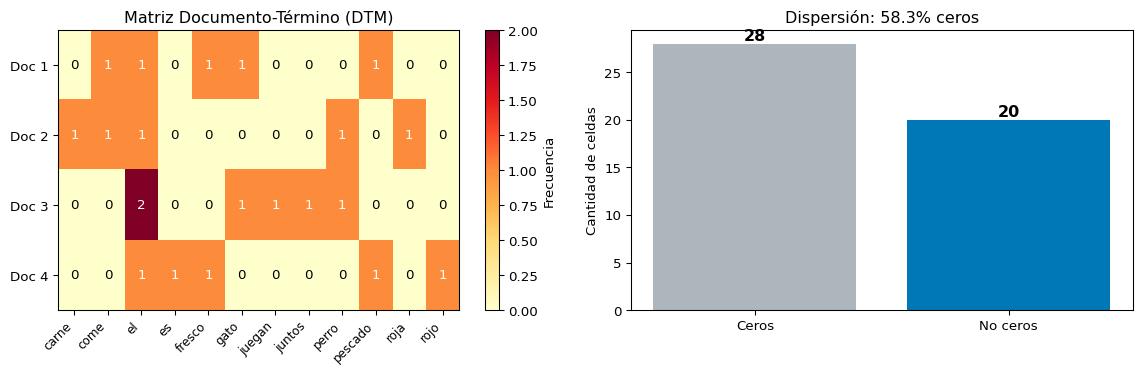
Variantes del Modelo BoW
1. Frecuencia Bruta (Raw Count)
\[\text{BoW}(t, d) = f(t, d)\]
Contar cuántas veces aparece el término \(t\) en el documento \(d\).
2. Binario (Presencia/Ausencia)
\[\text{BoW}(t, d) = \begin{cases} 1 & \text{si } t \in d \\ 0 & \text{si } t \notin d \end{cases}\]
Solo indicar si el término aparece o no.
3. Frecuencia Normalizada
\[\text{BoW}(t, d) = \frac{f(t, d)}{\sum_{t' \in d} f(t', d)}\]
Dividir por el total de palabras del documento.
4. Frecuencia Logarítmica
\[\text{BoW}(t, d) = \log(1 + f(t, d))\]
Reducir el impacto de palabras muy frecuentes.
Variantes en código
from sklearn.feature_extraction.text import CountVectorizer
import numpy as np
documentos = [
"el gato el gato el gato come pescado",
"el perro come carne"
]
# Raw count
cv_raw = CountVectorizer()
X_raw = cv_raw.fit_transform(documentos).toarray()
# Binario
cv_bin = CountVectorizer(binary=True)
X_bin = cv_bin.fit_transform(documentos).toarray()
# Normalizado
X_norm = X_raw / X_raw.sum(axis=1, keepdims=True)
# Logarítmico
X_log = np.log1p(X_raw)
vocabs = cv_raw.get_feature_names_out()
print(f"Vocabulario: {list(vocabs)}\n")
print(f"{'Variante':<14} Doc 1{' '*len(vocabs)*6} Doc 2")
print(f"{'Raw':14s} {X_raw[0]} {X_raw[1]}")
print(f"{'Binario':14s} {X_bin[0]} {X_bin[1]}")
print(f"{'Normalizado':14s} {np.round(X_norm[0], 3)} {np.round(X_norm[1], 3)}")
print(f"{'Logarítmico':14s} {np.round(X_log[0], 3)} {np.round(X_log[1], 3)}")Vocabulario: ['carne', 'come', 'el', 'gato', 'perro', 'pescado']
Variante Doc 1 Doc 2
Raw [0 1 3 3 0 1] [1 1 1 0 1 0]
Binario [0 1 1 1 0 1] [1 1 1 0 1 0]
Normalizado [0. 0.125 0.375 0.375 0. 0.125] [0.25 0.25 0.25 0. 0.25 0. ]
Logarítmico [0. 0.693 1.386 1.386 0. 0.693] [0.693 0.693 0.693 0. 0.693 0. ]Bloque 4: Similitud entre Documentos
¿Qué tan parecidos son dos documentos?
Con BoW, cada documento es un vector en un espacio de alta dimensión. Podemos medir la similitud entre ellos.
Similitud Coseno
\[\text{cos}(\vec{a}, \vec{b}) = \frac{\vec{a} \cdot \vec{b}}{||\vec{a}|| \cdot ||\vec{b}||}\]
- Mide el ángulo entre vectores
- Rango: [-1, 1] (en BoW: [0, 1])
- 1 = idénticos, 0 = sin relación
Distancia Euclídea
\[d(\vec{a}, \vec{b}) = \sqrt{\sum_i (a_i - b_i)^2}\]
- Mide la distancia entre puntos
- Rango: \([0, \infty)\)
- 0 = idénticos
- Sensible a la magnitud
¿Cuál usar?
Para comparar documentos de diferente longitud, la similitud coseno es preferible porque normaliza por la magnitud.
Ejemplo: Similitud entre Documentos
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.metrics.pairwise import cosine_similarity
import numpy as np
documentos = [
"el gato duerme en la alfombra", # Doc 1
"el perro duerme en la cama", # Doc 2
"la economía del país crece rápido", # Doc 3
"el gato juega con la pelota", # Doc 4
]
vectorizer = CountVectorizer()
X = vectorizer.fit_transform(documentos)
# Calcular similitud coseno
sim_matrix = cosine_similarity(X)
print("Matriz de Similitud Coseno:\n")
etiquetas = [f"Doc {i+1}" for i in range(len(documentos))]
print(f"{'':8s}", " ".join(f"{e:>6s}" for e in etiquetas))
for i, etiqueta in enumerate(etiquetas):
fila = " ".join(f"{sim_matrix[i][j]:>6.3f}" for j in range(len(documentos)))
print(f"{etiqueta:8s} {fila}")Matriz de Similitud Coseno:
Doc 1 Doc 2 Doc 3 Doc 4
Doc 1 1.000 0.667 0.167 0.500
Doc 2 0.667 1.000 0.167 0.333
Doc 3 0.167 0.167 1.000 0.167
Doc 4 0.500 0.333 0.167 1.000Visualización de Similitud
Code
import matplotlib.pyplot as plt
import numpy as np
fig, ax = plt.subplots(figsize=(6, 5))
etiquetas_cortas = [
"D1: gato duerme",
"D2: perro duerme",
"D3: economía",
"D4: gato juega"
]
im = ax.imshow(sim_matrix, cmap='Blues', vmin=0, vmax=1)
ax.set_xticks(range(len(etiquetas_cortas)))
ax.set_xticklabels(etiquetas_cortas, rotation=30, ha='right', fontsize=9)
ax.set_yticks(range(len(etiquetas_cortas)))
ax.set_yticklabels(etiquetas_cortas, fontsize=9)
ax.set_title('Similitud Coseno entre Documentos (BoW)', fontsize=12)
for i in range(len(documentos)):
for j in range(len(documentos)):
color = 'white' if sim_matrix[i][j] > 0.6 else 'black'
ax.text(j, i, f'{sim_matrix[i][j]:.2f}', ha='center', va='center',
fontsize=11, fontweight='bold', color=color)
plt.colorbar(im, label='Similitud')
plt.tight_layout()
plt.show()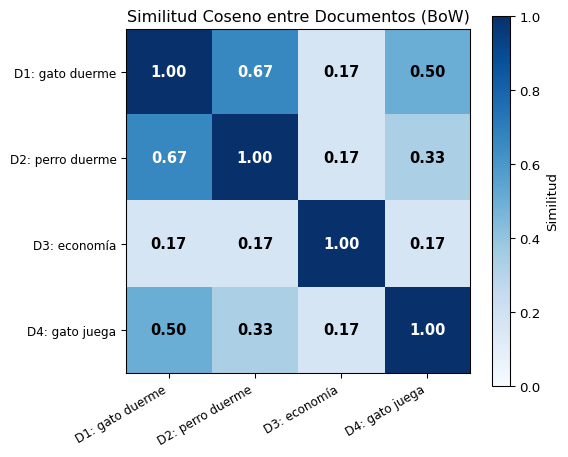
Aplicación: Clasificación Simple
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.naive_bayes import MultinomialNB
from sklearn.model_selection import cross_val_score
# Dataset de ejemplo: clasificar deportes vs. tecnología
textos = [
"el equipo ganó el partido de fútbol",
"el gol del delantero fue espectacular",
"el campeonato de tenis terminó ayer",
"el jugador se lesionó en el entrenamiento",
"la empresa lanzó un nuevo teléfono",
"el procesador del computador es rápido",
"la inteligencia artificial avanza rápido",
"el software tiene un error crítico",
]
etiquetas = ["deporte", "deporte", "deporte", "deporte",
"tecnología", "tecnología", "tecnología", "tecnología"]
# Crear representación BoW
vectorizer = CountVectorizer()
X = vectorizer.fit_transform(textos)
# Entrenar clasificador Naive Bayes
clf = MultinomialNB()
clf.fit(X, etiquetas)
# Predecir nuevos textos
nuevos = [
"el delantero marcó un gol increíble",
"el nuevo chip es más eficiente"
]
X_nuevo = vectorizer.transform(nuevos)
predicciones = clf.predict(X_nuevo)
for texto, pred in zip(nuevos, predicciones):
print(f"'{texto}' → {pred}")'el delantero marcó un gol increíble' → deporte
'el nuevo chip es más eficiente' → tecnologíaN-gramas: Más Allá de Palabras Sueltas
BoW pierde el orden. Los N-gramas capturan algo de contexto al considerar secuencias de N palabras consecutivas.
from sklearn.feature_extraction.text import CountVectorizer
texto = ["el gato negro come pescado fresco"]
# Unigramas (BoW clásico)
cv1 = CountVectorizer(ngram_range=(1, 1))
X1 = cv1.fit_transform(texto)
print(f"Unigramas: {cv1.get_feature_names_out().tolist()}")
# Bigramas
cv2 = CountVectorizer(ngram_range=(2, 2))
X2 = cv2.fit_transform(texto)
print(f"Bigramas: {cv2.get_feature_names_out().tolist()}")
# Unigramas + Bigramas
cv12 = CountVectorizer(ngram_range=(1, 2))
X12 = cv12.fit_transform(texto)
print(f"Uni+Bi: {cv12.get_feature_names_out().tolist()}")Unigramas: ['come', 'el', 'fresco', 'gato', 'negro', 'pescado']
Bigramas: ['come pescado', 'el gato', 'gato negro', 'negro come', 'pescado fresco']
Uni+Bi: ['come', 'come pescado', 'el', 'el gato', 'fresco', 'gato', 'gato negro', 'negro', 'negro come', 'pescado', 'pescado fresco']Explosión Combinatoria
Con bigramas, el vocabulario crece dramáticamente. Para un vocabulario de \(V\) palabras, hay hasta \(V^2\) bigramas posibles.
Parámetros Útiles de CountVectorizer
from sklearn.feature_extraction.text import CountVectorizer
documentos = [
"El procesamiento de lenguaje natural es increíble",
"El lenguaje natural humano es complejo",
"La inteligencia artificial procesa el lenguaje",
"El aprendizaje automático usa datos naturales",
"Los datos son el combustible de la inteligencia artificial"
]
# Parámetros avanzados
vectorizer = CountVectorizer(
max_features=10, # Solo las 10 palabras más frecuentes
min_df=2, # Aparece en al menos 2 documentos
max_df=0.9, # Aparece en máximo 90% de documentos
ngram_range=(1, 2), # Unigramas y bigramas
stop_words=None # Podemos pasar lista custom
)
X = vectorizer.fit_transform(documentos)
print(f"Vocabulario filtrado: {vectorizer.get_feature_names_out().tolist()}")
print(f"Forma de la matriz: {X.shape} (documentos × términos)")Vocabulario filtrado: ['artificial', 'datos', 'de', 'el lenguaje', 'es', 'inteligencia', 'inteligencia artificial', 'la', 'la inteligencia', 'lenguaje']
Forma de la matriz: (5, 10) (documentos × términos)Tip Práctico
min_df=2elimina palabras muy raras (posibles errores)max_df=0.8elimina palabras demasiado comunes (como stopwords)max_features=Nlimita la dimensionalidad
Bloque 5: Limitaciones y Comparación
Limitaciones de Bag of Words
1. Pierde el Orden 📝
Misma representación BoW, significado opuesto.
2. Alta Dimensionalidad 📏
- Vocabularios reales: 50K–500K palabras
- Matrices enormes y dispersas
- Costoso en memoria y cómputo
Solución: TF-IDF (Próxima Sesión)
Asignaremos pesos diferentes a cada término según su importancia relativa en el corpus.
One-hot vs. BoW: Comparación
| Aspecto | One-hot Encoding | Bag of Words |
|---|---|---|
| Nivel | Palabra | Documento |
| Representa | Identidad | Frecuencia |
| Dimensión | \(\|V\|\) | \(\|V\|\) |
| Captura semántica | ❌ No | ❌ No |
| Captura frecuencia | ❌ No | ✅ Sí |
| Orden | N/A | ❌ Perdido |
| Uso típico | Entrada de redes neuronales | Clasificación, clustering |
Mapa de Representaciones de Texto
Code
flowchart TD
A["🔢 Representaciones de Texto"] --> B["📊 Dispersas (Sparse)"]
A --> C["🧠 Densas (Dense)"]
B --> D["One-hot<br>✅ Hoy"]
B --> E["Bag of Words<br>✅ Hoy"]
B --> F["TF-IDF<br>📅 S2"]
C --> G["Word2Vec<br>📅 Semana 4"]
C --> H["GloVe<br>📅 Semana 4"]
C --> I["Embeddings<br>contextuales<br>📅 Semanas 9-10"]
style A fill:#0077b6,color:#fff
style D fill:#2a9d8f,color:#fff
style E fill:#2a9d8f,color:#fff
style F fill:#e9c46a,color:#000
style G fill:#f4a261,color:#000
style H fill:#f4a261,color:#000
style I fill:#e76f51,color:#fffflowchart TD
A["🔢 Representaciones de Texto"] --> B["📊 Dispersas (Sparse)"]
A --> C["🧠 Densas (Dense)"]
B --> D["One-hot<br>✅ Hoy"]
B --> E["Bag of Words<br>✅ Hoy"]
B --> F["TF-IDF<br>📅 S2"]
C --> G["Word2Vec<br>📅 Semana 4"]
C --> H["GloVe<br>📅 Semana 4"]
C --> I["Embeddings<br>contextuales<br>📅 Semanas 9-10"]
style A fill:#0077b6,color:#fff
style D fill:#2a9d8f,color:#fff
style E fill:#2a9d8f,color:#fff
style F fill:#e9c46a,color:#000
style G fill:#f4a261,color:#000
style H fill:#f4a261,color:#000
style I fill:#e76f51,color:#fff
Ejercicio Práctico
Mini Proyecto: Motor de Búsqueda Simple 🔍
Usando BoW + similitud coseno, creamos un buscador:
Code
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.metrics.pairwise import cosine_similarity
# Corpus de "artículos"
corpus = [
"La inteligencia artificial está transformando la medicina moderna",
"Los robots aprenden a cocinar platos gourmet con redes neuronales",
"El cambio climático afecta los glaciares de Bolivia",
"Python es el lenguaje más popular para ciencia de datos",
"Las redes neuronales artificiales imitan el cerebro humano",
"La deforestación en la Amazonía alcanza niveles récord",
"El aprendizaje automático mejora el diagnóstico médico",
]
vectorizer = CountVectorizer()
X = vectorizer.fit_transform(corpus)
def buscar(consulta, top_n=3):
"""Buscar documentos similares a la consulta."""
q_vec = vectorizer.transform([consulta])
similitudes = cosine_similarity(q_vec, X).flatten()
indices = similitudes.argsort()[::-1][:top_n]
print(f"🔍 Consulta: '{consulta}'\n")
for rank, idx in enumerate(indices, 1):
if similitudes[idx] > 0:
print(f" {rank}. (sim={similitudes[idx]:.3f}) {corpus[idx]}")
else:
print(f" {rank}. (sim=0.000) Sin resultados relevantes")
buscar("inteligencia artificial y medicina")
print()
buscar("medio ambiente y bosques")🔍 Consulta: 'inteligencia artificial y medicina'
1. (sim=0.548) La inteligencia artificial está transformando la medicina moderna
2. (sim=0.000) Sin resultados relevantes
3. (sim=0.000) Sin resultados relevantes
🔍 Consulta: 'medio ambiente y bosques'
1. (sim=0.000) Sin resultados relevantes
2. (sim=0.000) Sin resultados relevantes
3. (sim=0.000) Sin resultados relevantesResumen
Lo que Aprendimos Hoy ✅
One-hot Encoding:
- Un
1por palabra, resto0 - Dimensión = tamaño del vocabulario
- Sin similitud semántica
- Base para embeddings
Bag of Words:
- Vector de frecuencias por documento
- Matriz Documento-Término
- Variantes: binaria, normalizada, log
Similitud:
- Similitud coseno para comparar documentos
- Independiente de la longitud
Herramientas:
CountVectorizerde scikit-learn- Parámetros:
min_df,max_df,max_features,ngram_range
Para la Próxima Clase 📚
Semana 2, S2: TF-IDF — Encontrando lo relevante en un documento
Aprenderemos a asignar pesos inteligentes a las palabras según su importancia, no solo su frecuencia.
Lectura:
- Capítulo 6 (secciones 6.1-6.5): Speech and Language Processing (Jurafsky & Martin)
- Documentación de scikit-learn: CountVectorizer
Preparación:
- Revisar conceptos de álgebra lineal: vectores, producto punto, norma
¿Preguntas? 🙋
¡Gracias!
📧 fsuarez@ucb.edu.bo
🔗 Materiales: github.com/fjsuarez/ucb-nlp
NLP y Análisis Semántico | Semana 2